
Proactive Detection and Isolation of Congestion in IP-based SANs
Introduction
As all networking continues to consolidate around TCP/IP and Solid-State Disk (SSD) memory becomes a more pervasive form of storage, the Non-Volatile Memory Express (NVMe) standard is growing in use. Augtera Networks and Dell Technologies have partnered to create a NVMe/TCP solution with Network Performance Monitoring. Specifically, Augtera’s Network AI provides high-fidelity detection of the TCP flows impacted by congestion and identify the root of the congestion. In this blog, we describe how this is done, and the impact of AI/ML in delivering this solution. The solution can also be applied to other storage environments where TCP is used.
Congestion Detection
Storage performance and data integrity are critical requirements for IT teams. As a result, so too is congestion free and error free network infrastructure. The Augtera Network AI platform uses sFlow telemetry and purpose-built AI/ML algorithms to detect congestion, support rich query-based visualization, provide an end-to-end view including servers and virtual machines, and notify collaboration tools such as Slack and Enterprise ticketing solutions such as ServiceNow.
Purpose-built AI/ML algorithms enable high-fidelity detection with low false positives and low false negatives. In the NVMe/TCP use case, TCP selective acknowledgements (SACKs) provide a strong signal of TCP flow congestion, and specifically, lost packets between a TCP sender / receiver pair. SACKs can be detected using sFlow data. sFlow is supported by most switches, so no additional hardware is required.
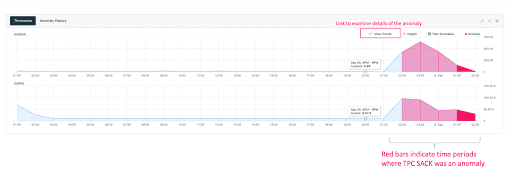
The above diagram is a screenshot of Augtera’s Network AI visualizing tcpSack anomalies, shown in red. sFlow sampling rates can be extremely high, for example 40,000 to one, so detected anomalies can represent millions of packets.
Identifying Impacted Flows
A network operations team can see the underlying data of an anomaly, in this case TCP flows, by clicking “View Trends.” For the anomaly above, the operator would see the server source IP addresses and storage destination IP addresses.
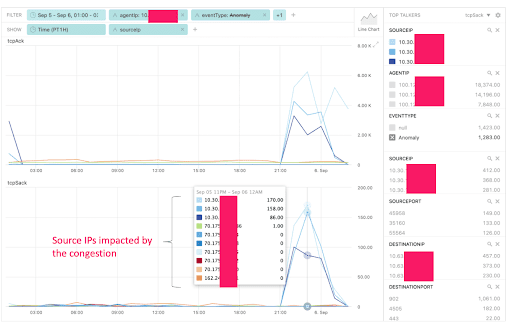
Network operators will often recognize IP addresses. In addition, Network AI can augment visualizations and notifications with customer meta data, for example device names
Incident Root
A Network Operations Teams will also want to know where packets are being dropped, so they can quickly initiate mitigation and remediation procedures. Network AI collects much more than TCP SACK / sFlow data, including total data in/out, discards, frame errors, optical levels and more. This provides end-to-end, multi-layer observability, enabling rapid determination of whether the incident root is the servers, switches, or switch interfaces. In addition, control plane protocols, for example BGP, can also be the root of data plane degradation. Network AI can also detect this.
Below left indicates that for the above incident, the servers are not the source of anomalies. On the other hand, the below right indicates that the switch fabric may be the root of anomalies because there is a spike in anomalies when the traffic rate changes.
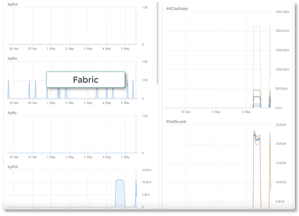
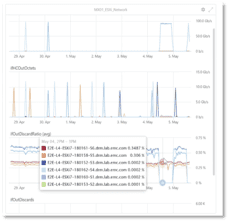
High-Fidelity Notification
It is critical that the right operations teams are notified with the best insights. Specifically, operationally irrelevant, and redundant data be eliminated. Purpose-built anomaly detection algorithms in conjunction with auto-correlation, ensure that relevant notifications are generated, with redundant data/alerts collapsed under a single incident.
Conclusion
NVMe/TCP is a critical building block for next generation storage networks. Augtera Network AI provides a high-fidelity solution for congestion detection, impact analysis, and root identification. Collaboration tools such as Slack and Enterprise ticketing solutions such as ServiceNow can be automatically notified, with notification noise dramatically reduced or eliminated.
Please come to our ONUG POC to see a demonstration.
Please read our solution brief to learn more.


